
大数据应用开发工程师专业的核心课程是Hadoop框架的学习,那么这个框架就类似于Java应用开发的SSH/SSM框架,都是Apache基金会或者其他Java开源社区团体的能人牛人开发的贡献给大家使用的一种开源Java框架。我一直在向学生说Java语言是王道就是这个道理,Java的核心代码是开源的,是经过全球能人牛人共同学习共同研发共同检验的,所以说Java是最经得住检验的语言,而且任何人都可以学习Java核心技术并且使用核心技术开发出像android一样的系统和Hadoop一样的框架。如果把编程的世界比作一棵树,那么Java是根,SSH和Hadoop这样的框架都是它开得枝散得叶。
由于大数据应用开发工程师是目前IT培训界最热门的专业,大数据技术人才是引领智能革命的弄潮儿,是智能时代最直接的受益者,这么重要的专业我一定要给大家讲解的详细透彻,以Hadoop生态圈为主,介绍目前大数据应用级开发工程师在工作当中所用到的全部技术,建议大家在学习大数据应用开发工程师专业之前,要有一定的Java基本语法和框架的学习经验。
开源的Hadoop大数据开发平台
hadoop是一个能够对大量数据进行分布式处理的软件框架,hadoop以一种可靠、高效、可伸缩的方式进行数据处理,用户之所以可以轻松的在hadoop上开发和运行处理海量数据的应用数据,是因为hadoop具有高可靠性、高扩展性、高效性、高容错性等优点。
hadoop大数据生态系统:
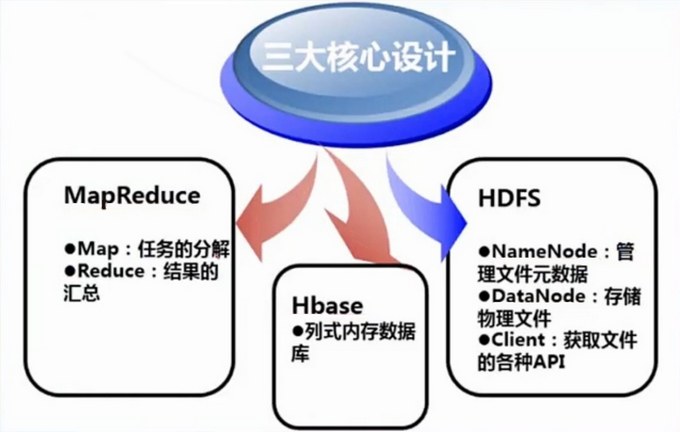
分布式文件系统-HDFS
提起hadoop文件系统,首先想到的是HDFS(Hadoop Distributed File System),HDFS是hadoop主要的文件系统,是Hadoop存储数据的平台,建立在网络上的分布式存储系统。hadoop还集成了其他文件系统,hadoop的文件系统是一个抽象的概念,HDFS只是其中的一种实现。
分布式计算框架-MapReduce
MapReduce是一种编程模型,是Hadoop处理数据的平台。用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
分布式开源数据库-Hbase
HBase – Hadoop Database,HBase是一个分布式的、面向列的开源数据库。适合于非结构化数据存储,保留数据多个时间段版本。Hbase极大的方便扩展了Hadoop对于数据的处理和应用。
大数据开发平台模块生态圈
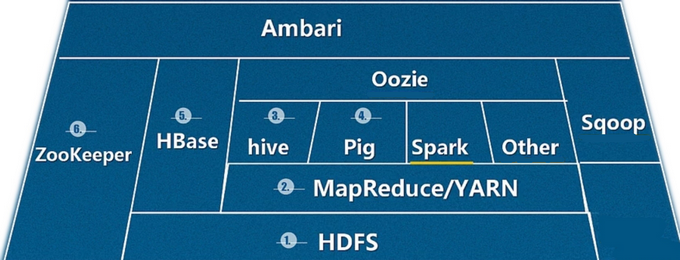
Hive
Hive是基于Hadoop的一个数据仓库工具,处理结构化SQL查询功能。可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行并提交到集群上去执行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,不用使用Java编程,十分适合数据仓库的统计分析。
学习Hive时,对于Hive QL中的DDL和DML就是必须要掌握的基础;表的定义、数据导出以及常用的查询语句的掌握是完成大数据统计分析的基础。学会针对Hive进行编程:使用Java API开操作Hive、开发Hive UDF函数。掌握好Hive部分高级的特性能大大提升Hive的执行效率。在优化过程中可以很好的借助于执行计划来进行分析,学习Hive时需要注意Hive性能优化是在生产中的最重要的环节,如何解决数据倾斜是关键; 梳理清楚Hive元数据各个表之间的关联关系也能提升对Hive的把握能力。
Pig
MapReduce之上高级过程编程脚本语言,用于查询大型半结构化数据集。
Zookeeper协调Hadoop生态圈各个模块共同工作
从英文含义上来看Hadoop是小象,Hive是蜜蜂,pig是猪,Zookeeper是动物管理员。那么很显然Zookeeper的作用是分布式应用程序协调服务,为各个模块提供一致性服务的。
数据导入导出框架Sqoop
Sqoop是一款开源的工具,英文含义是象夫,就是喂养大象的人,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
学习目标:
1.了解Sqoop是什么、能做什么及架构 ;
2.能够进行Sqoop环境部署 ;
3.掌握Sqoop在生产中的使用 ;
4.能够使用Sqoop进行ETL操作 。
Oozie
Oozie的英文含义是驯象人,非常形象,Oozie的作用是协调Hadoop各个模块数据处理任务,给它们安排一个工作计划。
Ambari
Ambari的英文含义可以理解为篱笆,这个模块开发者的意思是把Hadoop生态圈或者形象的叫做动物园围起来,负责各个模块部署安装,版本配合、升级。
大数据图形展示框架HUE
HUE是Cloudrea公司开源的,与Hadoop生态系统紧密结合的一个Web UI应用程序,可以通过Hue来查看、管理HDFS上面的文件,通过Hue从界面编写Hive的SQL语句对Hive进行查询,并使用图表直观的展示查询结果,可以与Oozie集成,用户创建和监控工作流程。
学习目标:
1.了解HUE是什么、能做什么及架构 ;
2.能够进行HUE环境部署 ;
3.掌握HUE在生产中的使用 。
Spark
Spark是目前最流行的大数据处理框架,以简单、易用、性能卓越著称。丰富的程序接口和库文件也使得Spark成为业内数据快速处理和分布式机器学习的必备工具。
学习目标:
1.了解Spark的组件和应用场景 ;
2.能够部署Spark Standalone模式 ;
3.能够使用Spark进行交互式开发 ;
4.能够发布独立应用程序并使用spark-submit 提交 。
5.掌握Pair RDD的操作 ;
6.掌握Pair RDD如何与一般RDD结合 ;
7.掌握RDD的输出操作 ;
8.了解RDD的持久化、累加器和广播变量 。
9.掌握DataFrame的操作 ;
10.掌握不同数据源的加载方法 ;
11.了解UDF的定义方法 。
12.掌握Spark图形化工具的查看 。
13.了解Spark Streaming的特点 ;
14.掌握流式处理的基本操作 ;
15.理解状态操作和窗口操作的概念 。
16.能够根据生产环境特点,组织基于spark sql 的周期任务完成基本日志系统的构建。
17.掌握不同需求下Spark组件的选择 ;
18.掌握Spark参数调优 ;
19.掌握各组件之间的调用及thrift接口的使用 。
20.了解Spark作为机器学习工具的优势 ;
21.了解机器学习算法的分类 ;
22.通过K-means算法进行玩家付费行为聚类 。
*扩展技能:
python开发基础、数据分析与数据挖掘
学习数据挖掘工具Sklearn,熟悉数据挖掘朴素贝叶斯算法和数据挖掘SVM分类算法,并且最终使用Sklearn实现贝叶斯以及SVM算法 。
Storm大数据分布式实时计算
Storm是分布式数据处理的框架,Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理,就好比 Hadoop 用于批处理。如果说MapReduce降低了并行批处理复杂性,Storm是降低了进行实时处理的复杂性。
Scala编程开发
Scala是一种函数式面向对象语言,类似于RUBY和GROOVY语言,它无缝结合了许多前所未有的特性形成一门多范式语言,其中高层并发模型适用于大数据开发。而同时又运行于JAVA虚拟机之上。